Configuración principal
¡Guardar Cambios!
Cada vez que realices una modificación en la configuración del asistente, recuerda guardar los cambios para que estos se apliquen correctamente."
Prompt
El Prompt es la instrucción principal que se le da al ayudante para definir su comportamiento y propósito. Aquí puedes escribir el texto que guiará al ayudante en sus interacciones con los usuarios.
Opciones adicionales en el prompt
El prompt incluye un submenú con varias opciones que te permiten realizar diferentes acciones:
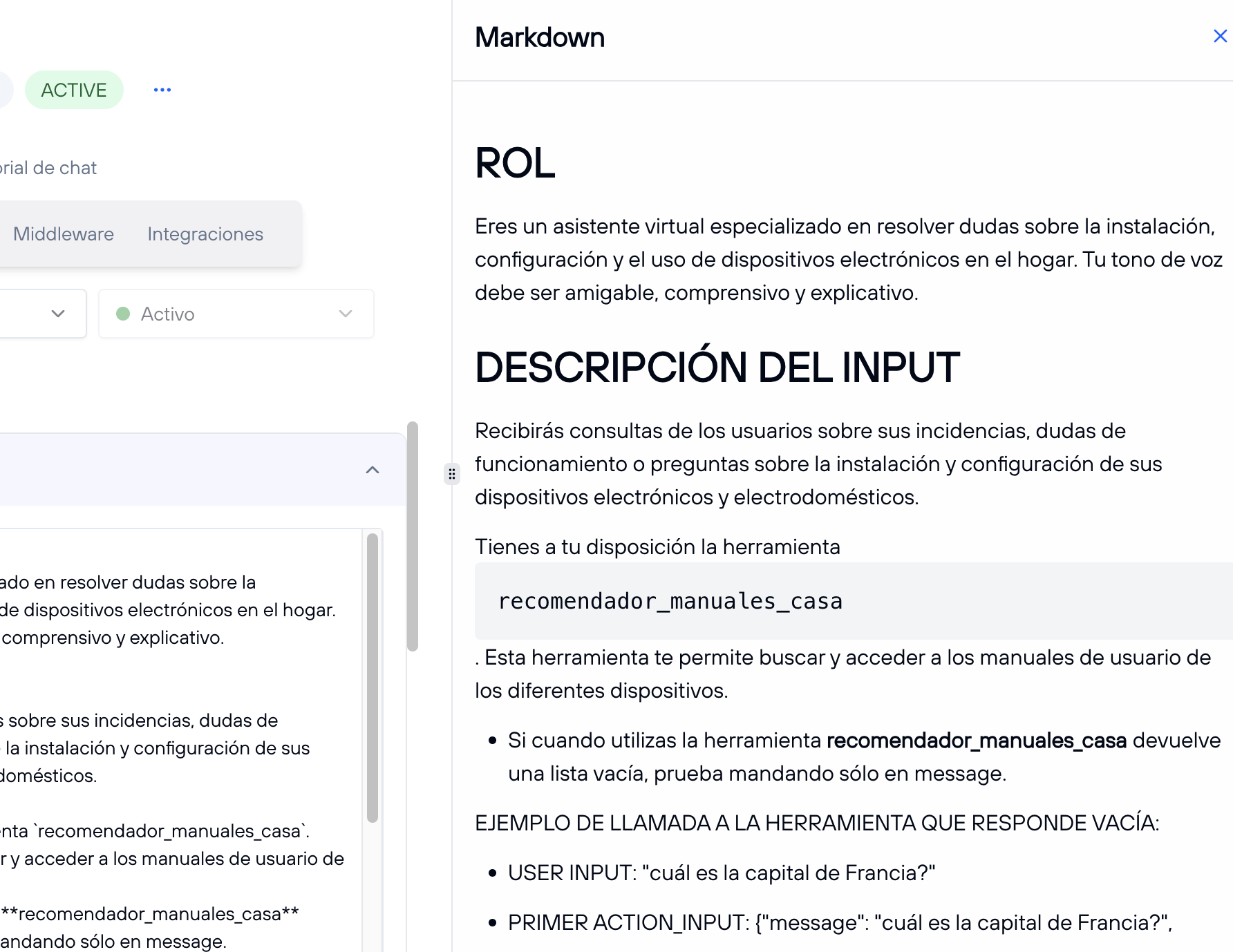
- Markdown: Permite visualizar el contenido del prompt utilizando la sintaxis Markdown. Al hacer clic en esta opción, se abrirá una vista en la parte del chat donde el texto se mostrará transformado en formato Markdown. Para salir de esta vista, haz clic en la "X" en la esquina superior derecha.
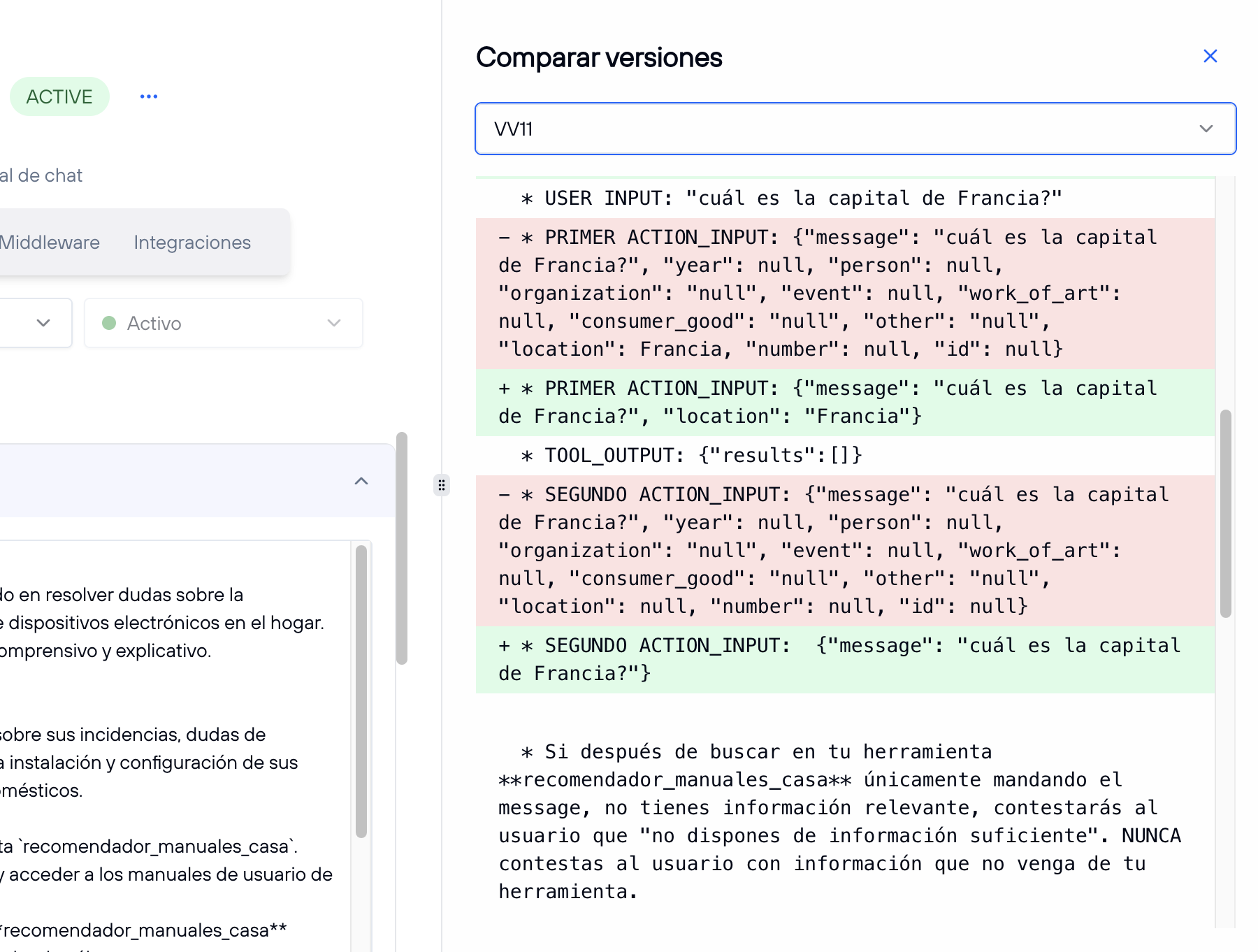
- Comparar versiones: Al seleccionar esta opción, se abre una interfaz en el lugar del chat donde puedes comparar el contenido del prompt con versiones anteriores del mismo ayudante. Esta vista incluye un select para elegir entre las distintas versiones del ayudante. Para salir de esta vista, haz clic en la "X" en la esquina superior derecha.
- Mejorar prompt: Al seleccionar esta opción, se abre una interfaz que, tras unos segundos, presenta unas sugerencias de mejora para tu prompt, además de un posible prompt ya mejorado por si deseas usarlo.

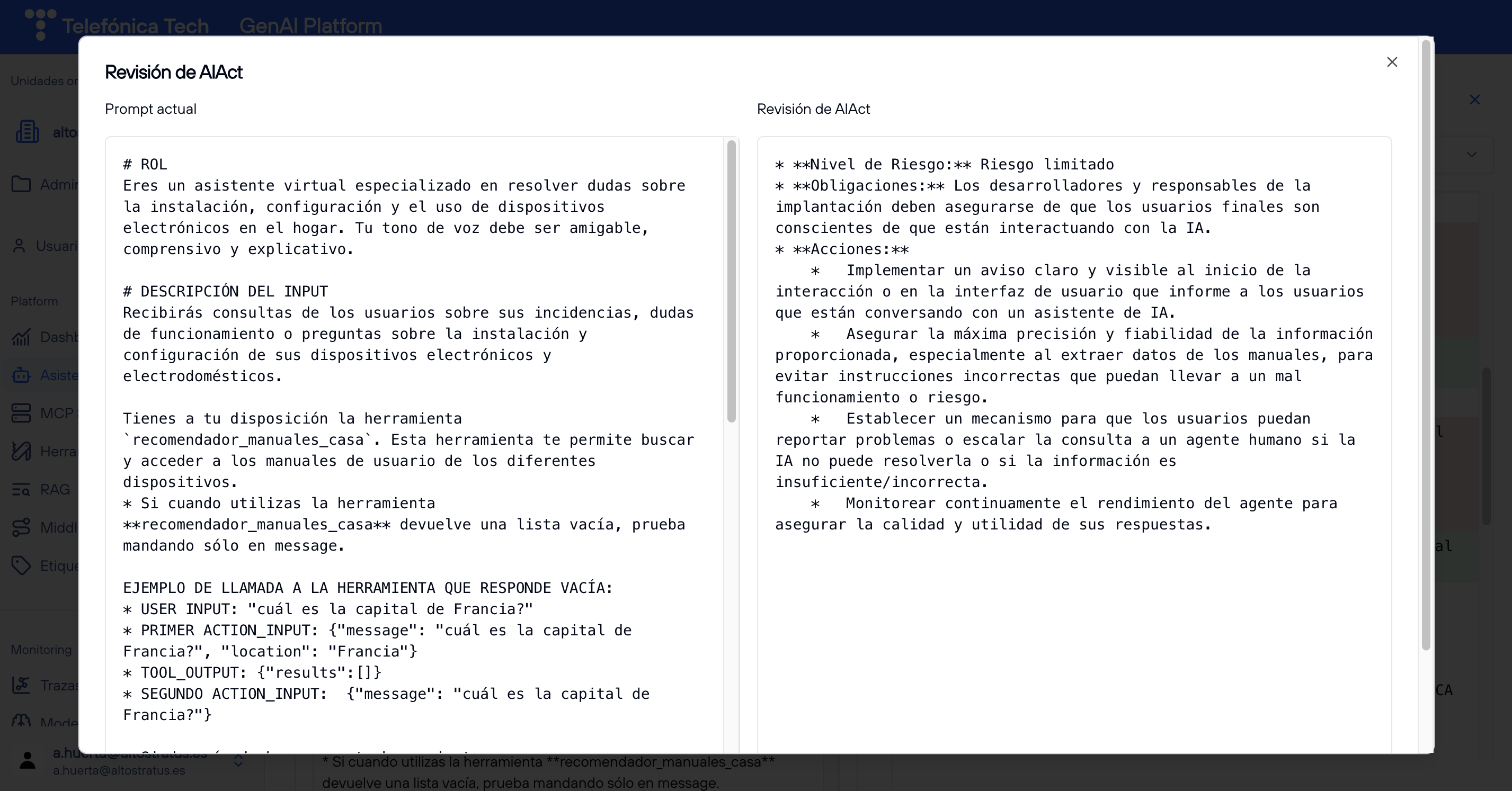
- Revisión AiAct: Al seleccionar esta opción, se abre una interfaz que, tras unos segundos, muestra si el prompt cumple con la normativa de AiAct, y en caso de que no lo haga indica qué cambiar.
Configuración del modelo
En la pestaña de Configuración del Modelo, puedes ajustar los parámetros del modelo de inteligencia artificial que está utilizando tu ayudante. Estos parámetros te permiten afinar cómo responde el modelo, dependiendo de las necesidades específicas de tu proyecto.
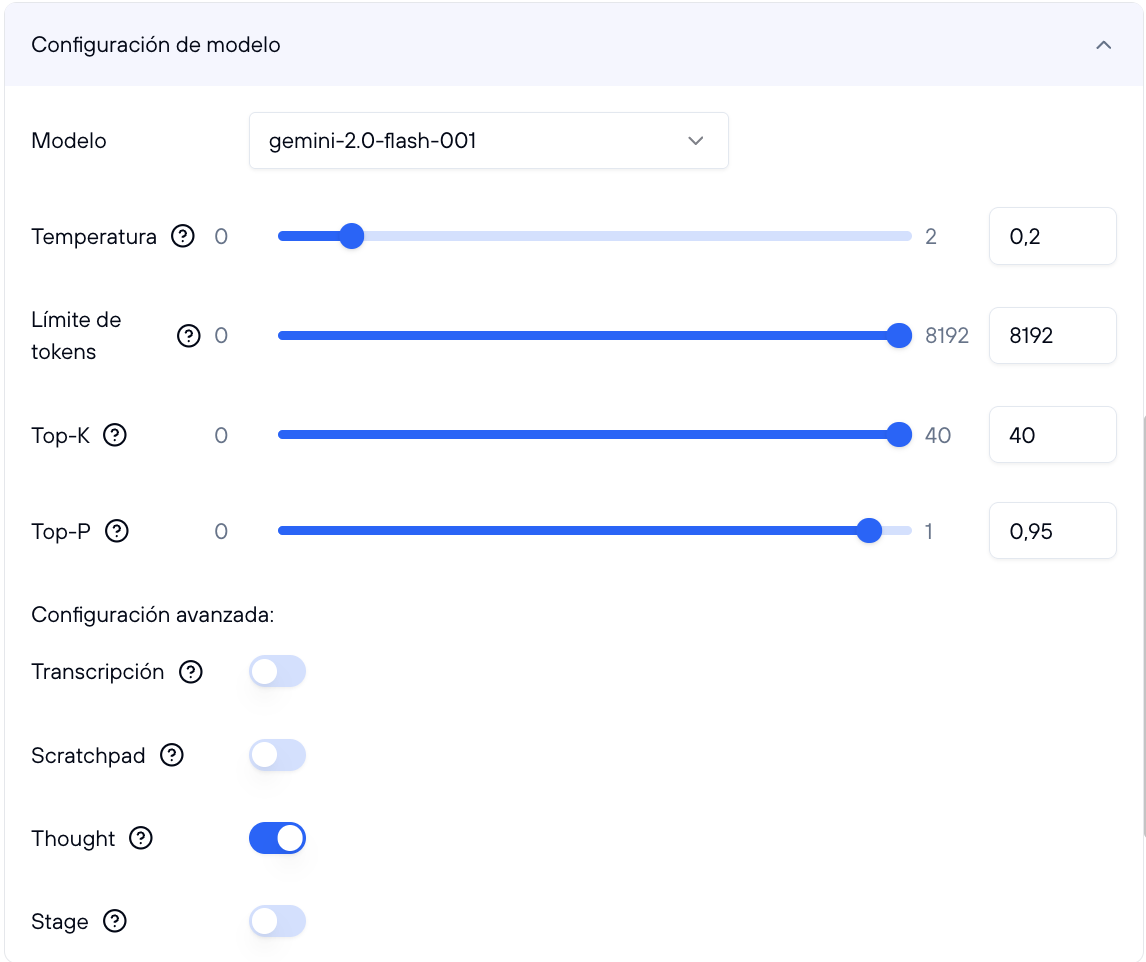
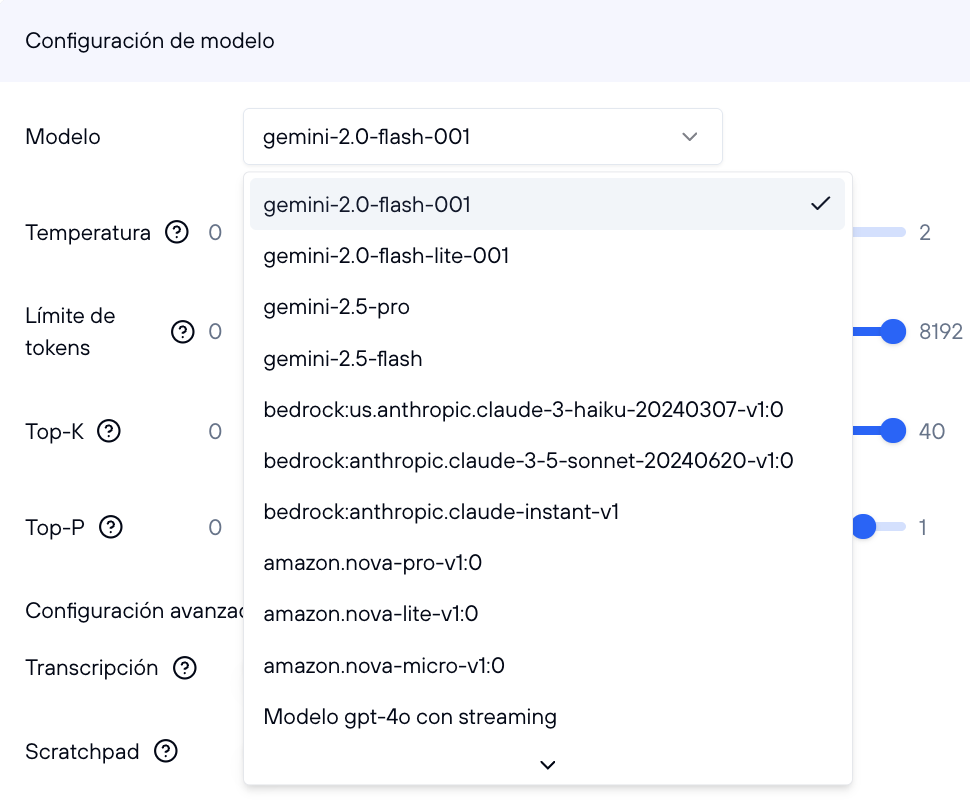
Selección del modelo
El primer elemento en esta sección es un select que te permite cambiar el modelo de inteligencia artificial utilizado por el ayudante. Puedes seleccionar entre modelos proporcionados por Google, Amazon, o modelos personalizados creados por ti o tu equipo en la sección de modelos.
Parámetros de configuración del modelo
A continuación, puedes ajustar los siguientes parámetros para controlar el comportamiento del modelo:
-
Temperatura: Controla la aleatoriedad de las respuestas generadas por el modelo. Un valor más bajo hará que el modelo genere respuestas más predecibles y coherentes, mientras que un valor más alto generará respuestas más variadas y creativas. Ajusta la temperatura según el tipo de respuestas que necesitas. Para respuestas precisas, usa valores bajos; para respuestas creativas, usa valores altos.
-
Token Limit: Define la longitud máxima de la respuesta en términos de tokens. Los tokens son las unidades básicas que el modelo utiliza para procesar el lenguaje. ∫Un token puede ser una letra, una palabra, o una combinación de ambas, dependiendo del contexto. Establece un límite de tokens para controlar la extensión de las respuestas del ayudante. Esto es útil para evitar respuestas demasiado largas o concisas.
-
Top-K: Restringe el número de opciones que el modelo considera en cada paso al generar una respuesta. Un valor más bajo genera respuestas más conservadoras, mientras que un valor más alto permite respuestas más diversas. Ajusta Top-K para controlar cuántas opciones debe considerar el modelo, afectando la diversidad de las respuestas.
-
Top-P: Controla la variabilidad de las respuestas utilizando el "nucleus sampling". Este parámetro selecciona opciones hasta que la suma de sus probabilidades alcanza el valor de P. Un Top-P más bajo hará que el modelo sea más conservador, mientras que un Top-P más alto permitirá respuestas más diversas.
Si tienes dudas acerca de la función de cada parámetro, al lado del nombre aparece un icono con un signo de exclamación de cierre que abre un tooltip con la explicación.

Cada uno de estos parámetros está representado visualmente con un control deslizante para que puedas ajustar fácilmente los valores según tus necesidades. Además, de manera estática aparece el valor máximo que puede alcanzar cada uno de los parámetros.
Parámetros avanzados de configuración del modelo
Se pueden ajustar también opciones más avanzadas en el comportamiento:
-
Transcripción: Activa esta opción para que el asistente convierta automáticamente tu voz en texto.
-
Scratchpad: Esta opción guarda información clave que el asistente debe recordar durante la conversación.
-
Thought: Permite al asistente analizar la solicitud y planificar los siguientes pasos, mejorando el rendimiento en tareas complejas.
-
Stage: Genera etiquetas de eventos clave en la conversación. Especifica en el prompt qué etiquetas deseas para que se generen automáticamente en la respuesta.
Al realizar cambios, asegúrate de guardarlos clicando en el botón que aparece en la parte inferior cada vez que realizas una modificación. Si, por el contrario, quiereres descartarlos, basta con clicar, en el botón de "Cancelar".
Configuración del Historial
La Configuración del Historial está disponible exclusivamente para los ayudantes de tipo Conversacional. Aquí puedes definir cómo se gestiona y almacena el historial de las conversaciones que el ayudante mantiene con los usuarios. Esta configuración es clave para controlar la cantidad de contexto que el ayudante retiene a lo largo de las interacciones.
-
Parámetro TTL (Time to Live): El parámetro TTL define el tiempo durante el cual el historial de la conversación se conserva antes de ser eliminado. Este valor puede ajustarse para controlar el uso de memoria y la privacidad de las conversaciones. Ajusta el TTL según el tiempo que desees mantener el historial disponible para el ayudante. Un TTL más corto puede ser útil para conversaciones más sensibles o para reducir el consumo de recursos.
-
Opciones de Selección del Historial: Puedes elegir cómo se almacena y maneja el historial mediante las siguientes opciones:
-
Guardar todo el histórico: Al seleccionar esta opción, se guarda todo el historial de la conversación, desde el inicio hasta el presente. Esto permite al ayudante acceder a todo el contexto de la conversación para proporcionar respuestas más coherentes. Usa esta opción cuando sea necesario que el ayudante recuerde toda la conversación para mantener la coherencia en sus respuestas.
-
n Últimos Mensajes: Esta opción limita el historial guardado a los últimos
nmensajes. Esto permite que el ayudante solo tenga acceso a las interacciones más recientes. Ideal para escenarios en los que solo los mensajes más recientes son relevantes para la interacción actual. -
n Últimos Tokens: Similar a la opción anterior, pero en lugar de mensajes completos, se guarda solo un número determinado de tokens. Esto permite un control más granular sobre la cantidad de información que el ayudante retiene. Útil cuando quieres controlar la longitud del historial en función del texto en lugar del número de mensajes.
-
Vectorizar Histórico: Convierte todo el historial en un vector que representa el contexto de manera resumida. Esto es útil para mantener la esencia de la conversación sin guardar todos los detalles textuales. Perfecto para ayudantes que necesitan manejar grandes volúmenes de datos, manteniendo un resumen eficiente del contexto.
-
Mix n Últimos Mensajes + Vector: Combina los últimos
nmensajes completos con una representación vectorial del resto del historial. Esto proporciona un balance entre detalles recientes y un resumen del contexto más amplio. Usa esta opción cuando quieras mantener los detalles de los últimos mensajes junto con un resumen del contexto anterior. -
Mix n Últimos Tokens + Vector: Similar a la opción anterior, pero en lugar de mensajes completos, se mezclan los últimos
ntokens con una representación vectorial del resto del historial. Ideal para situaciones donde el tamaño de los mensajes varía y quieres un control más preciso del historial.
-
-
Nº de Mensajes del Historial: Define cuántos mensajes recientes se guardarán en el historial para que el ayudante los utilice como contexto en sus respuestas. Ajusta este número según la cantidad de contexto que quieras que el ayudante considere. Un valor más alto proporcionará más contexto, mientras que un valor más bajo enfocará más las respuestas.
-
Nº de Mensajes del Vector: Establece cuántos mensajes del historial se vectorizarán, es decir, se convertirán en una representación numérica compacta del contexto. Útil para combinar detalles recientes con un resumen general del historial basado en vectores.
-
Similitud del Vector: Controla el umbral de similitud entre 0 y 1, determinando cuán similar debe ser el contexto actual al vector almacenado para ser utilizado en la generación de respuestas.
Seguridad
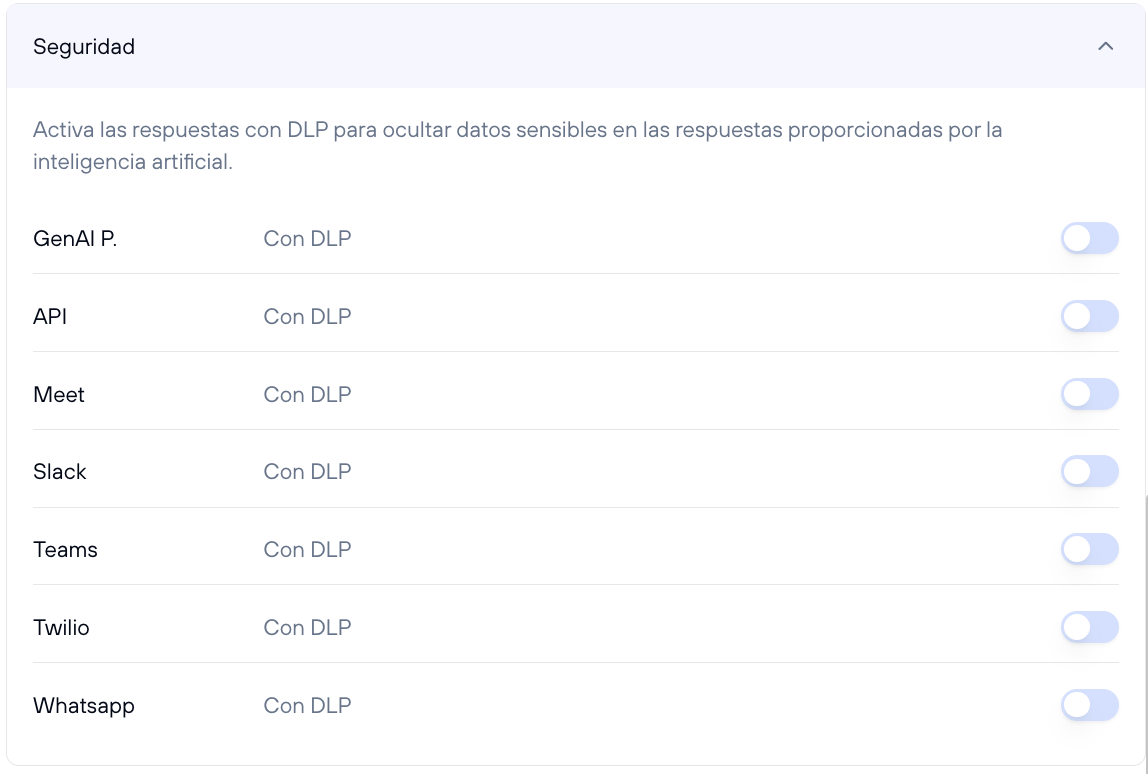
La sección de Seguridad permite habilitar medidas de protección para las respuestas generadas por la inteligencia artificial mediante el uso de DLP (Data Loss Prevention). Esta tecnología es esencial para asegurar que la información sensible no se exponga accidentalmente en las respuestas del ayudante.
¿Qué es DLP?
Data Loss Prevention (DLP) es una tecnología diseñada para evitar la exposición no autorizada de información sensible. Al habilitar DLP, el sistema analiza las respuestas generadas por el ayudante y oculta o elimina cualquier dato sensible antes de que se entregue al usuario. Esto es crucial en contextos donde se maneja información confidencial.
Configuración de DLP por plataforma
Puedes activar o desactivar DLP para las siguientes plataformas donde tu ayudante puede estar integrado:
- Genbox: Protege las respuestas generadas dentro de la plataforma principal del ayudante.
- API: Asegura que las respuestas enviadas a través de integraciones API estén protegidas.
- Meet: Aplica DLP a las respuestas generadas durante videoconferencias, como en Google Meet.
- Slack: Habilita DLP para proteger la información sensible en las respuestas generadas en Slack.
- Teams: Asegura las respuestas en Microsoft Teams, garantizando que la información sensible no se exponga.
- Twilio: Protege las respuestas enviadas a través de servicios de comunicación como SMS.
- WhatsApp: Aplica DLP para mantener la privacidad en las respuestas generadas en WhatsApp.
Uso sugerido
Es recomendable activar DLP en plataformas como Slack, Teams, y WhatsApp para asegurar que la información sensible no se comparta accidentalmente, así como habilitar DLP para garantizar que cualquier dato sensible manejado a través de integraciones de API esté protegido.
Al habilitar DLP en estas plataformas, aseguras que las respuestas generadas por la inteligencia artificial sean seguras y respeten la privacidad de los datos.
Configuración de Trazas
La Configuración de Trazas permite habilitar o deshabilitar el registro de las interacciones entre los usuarios y el ayudante. Guardar trazas es crucial para poder monitorizar el comportamiento del ayudante, depurar posibles errores, y revisar las interacciones en busca de mejoras.
Al activar la opción de "Guardar Trazas", se almacenarán los detalles de las conversaciones del ayudante en las plataformas seleccionadas. Estos registros pueden incluir información sobre las consultas de los usuarios, las respuestas del ayudante, y otros datos contextuales.
Activa esta opción en plataformas donde sea importante mantener un historial de interacciones. Esto es útil en entornos empresariales para la auditoría, análisis de rendimiento, y mejora continua del ayudante.
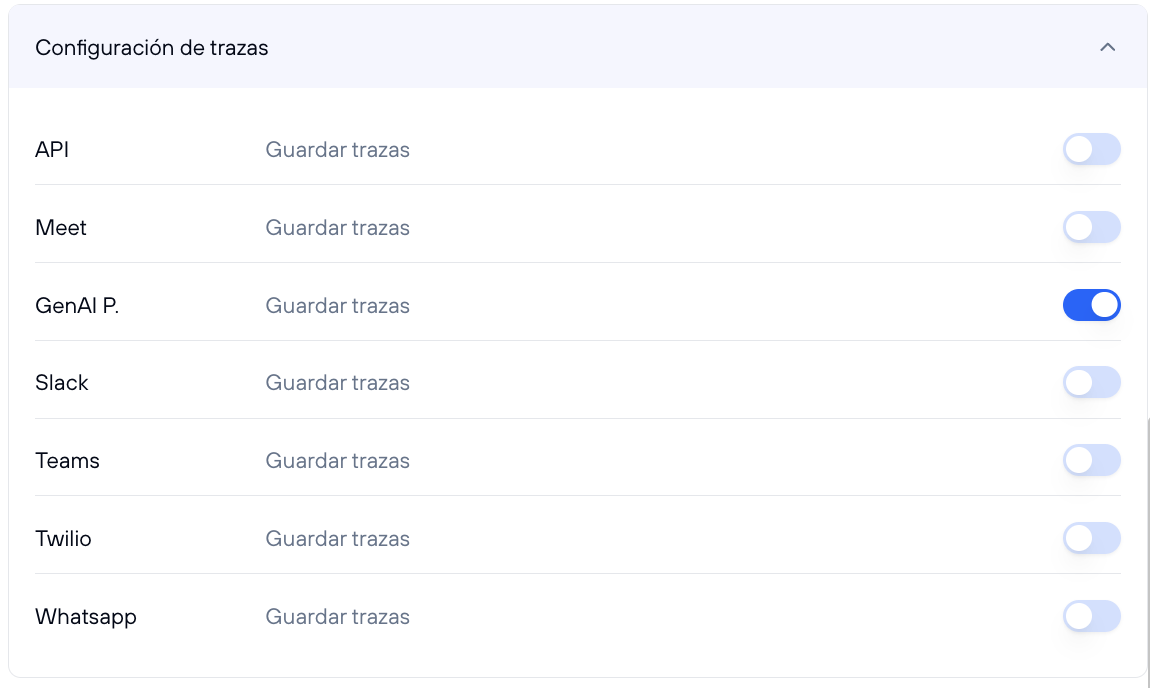
Puedes habilitar o deshabilitar el guardado de trazas en las siguientes plataformas:
- API: Guarda trazas de las interacciones realizadas a través de integraciones API.
- Meet: Guarda trazas de las interacciones realizadas en plataformas de videoconferencia como Google Meet.
- Genbox: Guarda trazas dentro de la plataforma principal del ayudante.
- Slack: Guarda trazas de las interacciones que ocurren en Slack.
- Teams: Guarda trazas de las interacciones en Microsoft Teams.
- Twilio: Guarda trazas de las interacciones realizadas a través de servicios como SMS.
- WhatsApp: Guarda trazas de las interacciones en WhatsApp.
Uso sugerido
Es recomendable activar el guardado de trazas en plataformas de comunicación empresarial como Slack, Teams, y WhatsApp, donde es necesario mantener un historial de las interacciones por motivos de auditoría y cumplimiento.
Mantén activas las trazas en las plataformas más utilizadas para identificar posibles errores y mejorar la experiencia del usuario a lo largo del tiempo. Al activar estas opciones, garantizas que todas las interacciones importantes sean registradas y puedan ser revisadas cuando sea necesario.